User Guide
Introduction
Getting Started
Topics
Kubernetes Cluster API Provider Hivelocity
⚠ This project is in the development stage. DO NOT USE IN PRODUCTION! ⚠
The Hivelocity Provider is a Kubernetes-native tool that allows you to manage Kubernetes clusters on Hivelocity’s infrastructure.
It offers options for high availability with instant bare metal and simplifies the process of creating, updating, and operating production-ready clusters.
You can find more information about Hivelocity and their infrastructure at hivelocity.net.
📰 What is the Cluster API Provider Hivelocity?
Cluster API is an operator that manages infrastructure similarly to how Kubernetes manages containers. It uses a declarative API and includes controllers that ensure the desired state of the infrastructure is maintained. This approach, referred to as Infrastructure as Software, allows for more automatic reactions to changes and problems compared to Infrastructure as Code solutions.
The Cluster API Provider Hivelocity (CAPHV) is the infrastructure component of the Cluster API stack. It enables the use of the Cluster API on Hivelocity’s infrastructure, facilitating the creation of stable and highly available Kubernetes clusters. This allows organizations to benefit from the advantages of declarative infrastructure and cost-effectiveness on a global scale. The Hivelocity Provider enables the creation of stable and highly available Kubernetes clusters on certified HIPAA, PCI, ISAE-3402, SSAE 16 SOC1, and SOC2 infrastructure around the globe.
With the Cluster API Provider Hivelocity, you can trust that your infrastructure is in good hands with a provider that has a track record of dynamic performance, static pricing, and a global presence.
📞 Support
If you want to manage Kubernetes yourself, please contact Hivelocity to set up your infrastructure.
If you have questions regarding running (production-ready) clusters with CAPHV, then ask Syself.
✨ Features
- Native Kubernetes manifests and API
- Manages the bootstrapping of networking and devices
- Choice of Linux distribution
- Support for single and multi-node control plane clusters (HA Kubernetes)
- Does not use SSH for bootstrapping nodes
- Day 2 operations including updating Kubernetes and nodes, scaling, and self-healing
- Custom CSR approver for approving kubelet-serving certificate signing requests (coming soon)
- Support for both Hivelocity instant bare metal and custom dedicated setups
🚀 Get Started
If you’re looking to jump straight into it, check out the Quick Start Guide
🔥 Compatibility with Cluster API and Kubernetes Versions
Please see: Versions
NOTE: As the versioning for this project is tied to the versioning of Cluster API, future modifications to this policy may be made to more closely align with other providers in the Cluster API ecosystem.
📖 Documentation
Please see our book for in-depth documentation.
❓ Questions
- If you have a question related to hardware: Hivelocity
- If you have a question related to the Cluster API Provider Hivelocity: Github Discussions
- If you need commercial support for Cluster API Provider Hivelocity: Syself
👥 Getting Involved and Contributing
Are you interested in contributing to Cluster API Provider Hivelocity? We, the maintainers and community, would love your suggestions, contributions, and help! If you want to learn more about how to get involved, you can contact the maintainers at any time.
To set up your environment, check out the development guide.
In the interest of getting more new people involved, we tag issues with good first issue. These are typically issues that have a smaller scope but are a good way to get acquainted with the codebase.
We also encourage ALL active community participants to act as if they are maintainers, even if you don’t have “official” write permissions. This is a community effort, and we are here to serve the Kubernetes community. If you have an active interest and you want to get involved, you have real power! Don’t assume that the only people who can get things done around here are the “maintainers”.
We would also love to add more “official” maintainers, so show us what you can do!
💫 Code of Conduct
Participation in the Kubernetes community is governed by the Kubernetes Code of Conduct.
🚧 Github Issues
🐛 Bugs
If you think you have found a bug, please follow these steps. Even if it just a small typo in the docs, please tell us how we can improve the project!
- Take some time to do due diligence in the issue tracker. Your issue might be a duplicate.
- Get the logs from the cluster controllers and paste them into your issue.
- Open a bug report.
- Give it a meaningful title to help others who might be searching for your issue in the future.
- If you have questions, reach out to the Cluster API community on the Kubernetes Slack channel.
⭐ Tracking New Features
We also use the issue tracker to track features. If you have an idea for a feature, or think that you can help Cluster API Provider Hivelocity become even more awesome, then follow these steps:
- Open a feature request.
- Give it a meaningful title to help others who might be searching for your issue in the future.
- Clearly define the use case. Use concrete examples, e.g. “I type
thisand Cluster API Provider Hivelocity doesthat”. - Some of our larger features will require some design. If you would like to include a technical design for your feature, please include it in the issue.
- After the new feature is well understood and the design is agreed upon, we can start coding the feature. We would love it if you could code it. So please open up a WIP (work in progress) pull request. Happy coding!
➡ Next
Getting Started
Terminology
Before we begin we need to answer some questions.
What is Hivelocity?
Hivelocity provides Dedicated Servers, Colocation and Cloud Hosting services to customers from over 130 countries since 2002. Hivelocity operates over 70,000 sq ft of data center space offering services in Tampa FL, Miami FL, Atlanta GA, New York NY, and Los Angeles CA. Each of Hivelocity’s data centers are HIPAA, PCI, ISAE-3402, SSAE 16 SOC1 & SOC2 certified.
What is Kubernetes?
Kubernetes is an open-source container orchestration system for automating software deployment, scaling, and management. Originally designed by Google, the project is now maintained by the Cloud Native Computing Foundation.
Kubernetes defines a set of building blocks that collectively provide mechanisms that deploy, maintain, and scale applications based on CPU, memory or custom metrics.
Source: Wikpedia
What is Cluster API?
Cluster API is a Kubernetes sub-project focused on providing declarative APIs and tooling to simplify provisioning, upgrading, and operating multiple Kubernetes clusters.
The Cluster API project uses Kubernetes-style APIs and patterns to automate cluster lifecycle management for platform operators. The supporting infrastructure, like virtual machines, networks, load balancers, and VPCs, as well as the Kubernetes cluster configuration are all defined in the same way that application developers operate deploying and managing their workloads. This enables consistent and repeatable cluster deployments across a wide variety of infrastructure environments.
Source: cluster-api.sigs.k8s.io
Cluster API uses Kubernetes Controllers: In a management-cluster runs a controller which reconciles the state of workload-clusters until the state reaches the desired state.
The desire state gets specified in yaml manifests.
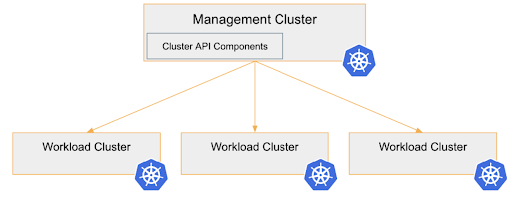
After the workload-cluster was created successfully, you can move the management-cluster into the workload-cluster. This gets done with clusterclt move. See Cluster API Docs “pivot”
What is Cluster API Provider Hivelocity?
Cluster API Hivelocity adds the infrastructure provider Hivelocity to the list of supported providers. Other providers supported by Cluster API are: AWS, Azure, Google Cloud Platform, OpenStack … (See complete list)
Setup
At this moment we only support cluster management with Tilt. So follow below instructions to create management and workload cluster.
Create a management cluster
Please run below command and this will use tilt-provider.yaml to create the provider and
.envrc to get all the environment variables.
# Please run the command from root of this repository
make tilt-up
Create workload cluster
There is a button in top right corner of the Tilt console to create the workload cluster.

Tear down resources
There is a button in top right corner of the Tilt console to create the workload cluster.

Once done delete management cluster by -
make delete-mgt-cluster
Current Limitations
Limitation: Missing Loadbalancers
Up to now Loadbalancers are not supported yet. But we are working on it.
See issue #55
Limitation: Missing VPC Networking
Up to now the machines have public IPs.
For security nodes should not be accessible from the public internet.
See issue #78
Current Known Issues
Known Issue: Broken Machine State
Sometimes machines get stuck. The hang in state “Reloading” forever. Then the support of Hivelocity need to reset the machine.
Related issue at Github #59.
Current State: alpha
Up to now CAPHV is not in the official list of infrastructure providers.
But we are working on it.
Please have a look at the Developer Guide, if you want to setup a cluster.
Navigation in the docs
On the left and right side of the documentation you see angle brackets. You can use them to switch to the next/previous page.
Topics
This section provides details for some of the operations that need to be performed when managing clusters.
Provisioning Machines
How can the CAPHV controller know which machines are free to use for a cluster?
You don’t want existing machines in your account to get re-provisioned to cluster nodes :-)
When starting a cluster you define a worker-machine-type and a control-plane-machine-type. Both values can be equal, when you don’t want to differentiate between both types.
Before you create your cluster you need to tag the devices accordingly.
The devices must have caphv-use=allow tag so that the controller can use them.
For example you set tags “caphvlabel:deviceType=hvControlPlane” on all machines which should become control planes, and “caphvlabel:deviceType=hvWorker” on all machines which should become worker nodes.
You can use the web-GUI of Hivelocity for this.
Then the CAPHV controller is able to select machines, and then provision them to become Kubernetes nodes.
The CAPHV controller uses Cluster API bootstrap provider kubeadm to provision the machines.
⚠ If you create a cluster with make tilt-up or other Makefile targets, then all machines having a
corresponding caphvlabel:deviceType= will get all their tags cleared. This means the machine is free to use,
and it is likely to become automatically provisioned. This means all data on this machine gets lost.
TODO: https://github.com/hivelocity/cluster-api-provider-hivelocity/issues/73
Environment Variables
You need the environment variables HIVELOCITY_API_KEY and KUBECONFIG.
We use direnv. This handy tools sets environment variables, as soon
as you enter a directory. The tool direnv does this by reading the file .envrc.
It is up to you, how you set the environment variables. You can use a different tool, too.
We provided an example file .envrc.example, which you should adapt to your environment.
make watch
make watch is an ad-hoc monitoring tool that checks whether the management cluster and the workload cluster
are operational.
It’s main use-case is to monitor the bootstrapping of new clusters.
It is not a replacement for a professional monitoring solution.
If there is an error, then make watch will show it (❌).
Please create a Github Issue if make watch does not detect an error.
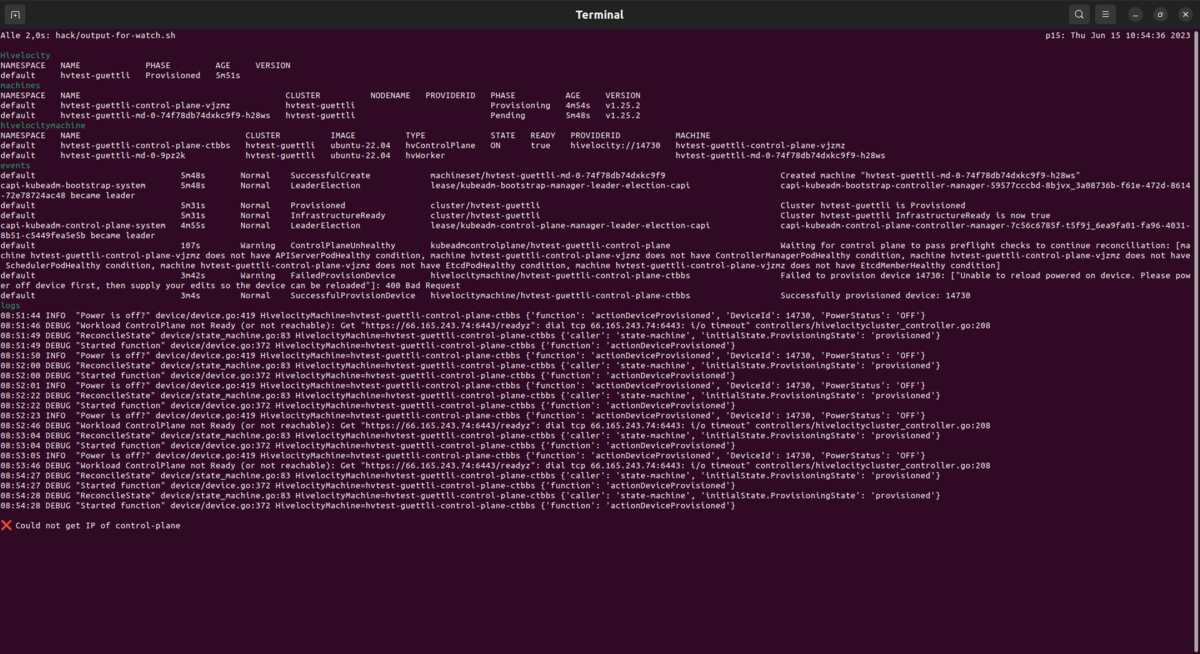
When the cluster starts some errors are common.
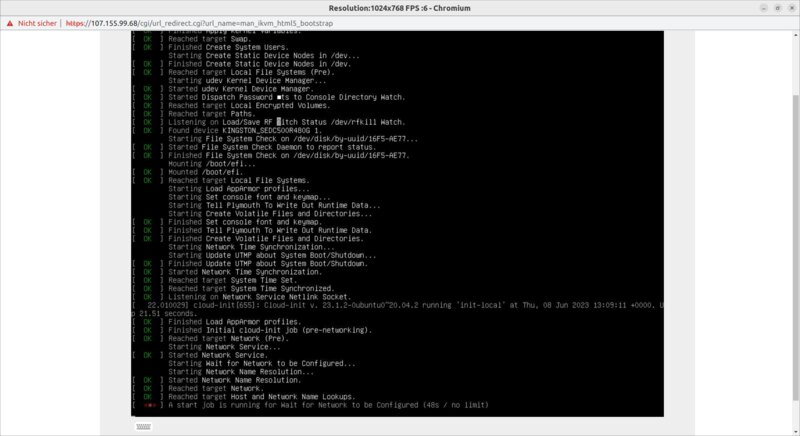
For example it will take up to 22 minutes until the ssh port of the first control plane is reachable.
Here a screenshot, six minutes after the Cluster and MachineDeployment manifests got applied to the management-cluster.
Hivelocity API
Hivelocity provides a rich API which you can access and test with your web browser:
developers.hivelocity.net/reference
APIs
Here are some API which gets used by CAPHV:
get_bare_metal_device_resource
Get all devices. CAPHV uses this API to search for devices which are free to get provisioned.
get_bare_metal_device_id_resource
Get a single device. CAPHV uses this API to read the tags of a single device.
put_bare_metal_device_id_resource
Update/reload instant device. CAPHV uses this API to provision a device.
Provisioning gets done via cloud-init
post_ssh_key_resource
Add public ssh key
put_device_tag_id_resource
Update device tags. CAPHV uses this API to ensure that device is part of exactly one cluster.
Client Go
CAPHV uses hivelocity-client-go to access the API from the programming language Golang.
This client gets automatically created from the swagger.json file provided by Hivelocity.
Hivelocity IPMI
Hivelocity provides an IPMI interface, which gives you (among many other things), a web UI to see the provisioning process of machines.
Clarifying Scope
Managing a production-grade Kubernetes system requires a seasoned team of experts.
The Cluster API Provider Hivelocity (CAPHV) plays a specific, limited role within this intricate ecosystem. It deals with the low-level lifecycle management of machines and infrastructure. While it can support the creation of production-ready Kubernetes clusters, it does not define the specific contents within the cluster. This important task is something that needs to be handled independently.
Please bear in mind, the standalone utility of this software is not intended to be production-ready!
Here are several aspects that CAPHV will not handle for you:
- production-ready node images
- secured kubeadm configuration
- incorporation of cluster add-ons, such as CNI or metrics-server
- testing & update procedures
- backup procedures
- monitoring strategies
- alerting systems
- identity and Access Management (IAM)
The Cluster API Provider Hivelocity simply equips you with the capacity to manage a Kubernetes cluster using the Cluster API (CAPI). The security measures and defining characteristics of your Kubernetes cluster have to be addressed by you, or expert professionals should be consulted for the same.
Please note that ready-to-use Kubernetes configurations, production-ready node images, kubeadm configuration, cluster add-ons like CNI and similar services need to be separately prepared or acquired to ensure a comprehensive and secure Kubernetes deployment.
CSR Controller
In public key infrastructure (PKI) systems, a certificate signing request (also CSR or certification request) is a message sent from an applicant to a certificate authority of the public key infrastructure in order to apply for a digital identity certificate. It usually contains the public key for which the certificate should be issued, identifying information (such as a domain name) and a proof of authenticity including integrity protection (e.g., a digital signature).
Source: Wikipedia
Quoting Enabling signed kubelet serving certificates
By default the kubelet serving certificate deployed by kubeadm is self-signed. This means a connection from external services like the metrics-server to a kubelet cannot be secured with TLS. … One known limitation is that the CSRs (Certificate Signing Requests) for these certificates cannot be automatically approved by the default signer in the kube-controller-manager - kubernetes.io/kubelet-serving. This will require action from the user or a third party controller.
The CAPHV CSR Controller signs kubelet-serving certs, since this is not done by Kubernetes or kubeadm up to now.
Related: List of Kubernetes Signers
The good news for you: You don’t need to do anything. It is enabled by default.
The CAPHV CSR controller will automatically sign the CSRs of the kubelets.
Alternative solutions would be:
- Use a tool like postfinance/kubelet-csr-approver
- Use self-signed certs and access the kubelet with insecure TLS. For example metrics-server.
- Approve CSR by hand (kubectl)
Developer Guide
You are welcome. We love Pull-Requests to improve the code.
Please contact us, if you want to improve something.
TODO: how to contact?
Repository Layout
├── .envrc.example # We use direnv to set environment variables. This is optional.
| # See https://direnv.net/.
|
├── .github # GitHub config: PR templates, CI, ...
|
├── api # This folder is used to store types and their related resources (Go code)
| # present in CAPHV.
| # The API folder has subfolders for each supported API version.
|
├── _artifacts # This directory is created during e2e tests.
| # It contains yaml files and logs.
|
├── bin # Binaries, mostly for envtests.
|
├── config # This is a Kubernetes manifest folder containing application
| # resource configurations as
| # kustomize YAML definitions. These are generated from other folders in the
| # repo using`make generate-manifests`.
| # More details are in the upstream docs:
| # https://cluster-api.sigs.k8s.io/developer/repository-layout.html#manifest-generation
|
├── controllers # This folder contains reconciler types which provide access to CAPHV controllers.
| # These types can be used by users to run any of the Cluster API controllers in an external program.
|
├── docs # Source for: https://hivelocity.github.io/cluster-api-provider-hivelocity/
|
├── hack # This folder has scripts used for building, testing, and the developer workflow.
│ └── tools/bin # Binaries like kustomize, tilt, ctlptl ... (Intalled via the Makefile)
|
├── main.go # This contains the main function for CAPHV. The code gets compiled to the binary `manager`.
|
├── Makefile # Configuration for building CAPHV. Try `make help` to get an overview.
|
├── pkg # Go code used to implement the controller.
├── templates
│ ├── cilium # CNI for workload clusters (you can choose a different CNI, too).
│ └── cluster-templates # YAML files for the management cluster.
|
├── test # Config and code for e2e tests.
|
├── Tiltfile # Configuration for https://tilt.dev/.
└── tilt-provider.yaml
# Setup a Development Environment
Tagging Machines
First you need to tag machines, so that the CAPHV controller can select and provision them. The devices must have caphv-use=allow tag so that the controller can use them.
See Provisioning Machines for more about this.
make tilt-up and other Makefile targets call go run ./test/claim-devices-or-fail to claim all devices
with a particular tag. But be careful, since all machines with this tag will get all existing tags removed.
Don’t accidentally “free” running machines this way.
SSH-Key
The machines, which get provisioned by CAPHV have a SSH public key installed, so that you can connect to the machine via ssh.
By default the ssh-key gets stored in the two files ~/.ssh/hivelocity and ~/.ssh/hivelocity.pub.
If the key pair does not exist yet, it will get created by the Makefile.
The keys get uploaded with go run ./cmd upload-ssh-pub-key ssh-key-hivelocity-pub ~/.ssh/hivelocity.pub. But for most cases this gets automatically handled for you by the scripts.
hack directory
The directory hack contains files to support you. For example the directory hack/tools/bin contains
binaries (envsubst and kustomize) which are needed to create yaml templates.
To make your setup self-contained, these binaries get created if you execute a matching makefile target for the first time.
API Key
Create a HIVELOCITY_API_KEY and add it to your .envrc file.
You can create this key via the web UI: my.hivelocity.net/account.
Kind
During development the management-cluster runs in local kind cluster.
The tool kind gets installed into hack/tools/bin/ automatically via the Makefile.
Using Tilt for Cluster API Provider Hivelocity
We use Tilt to start a development cluster.
Setting Tilt up
You need to create a .envrc file and specify the values you need. In the git repo is already a file. You can adapt it to your needs.
Machines with the corresponding caphvlabel:deviceType= tag will get conditionless provisioned. Be sure that you don’t provision machines which run valuable workload!
We recommend to use custom device tags for testing.
More about this topic: Provisioning Machines
Starting Tilt
make tilt-up
This will:
- install Tilt into
hack/tools/bin. - create a local container registry with
ctlptl. - create a management-cluster in Kind
- start Tilt
You need to press “SPACE” to open a web browser with the URL: http://localhost:10350
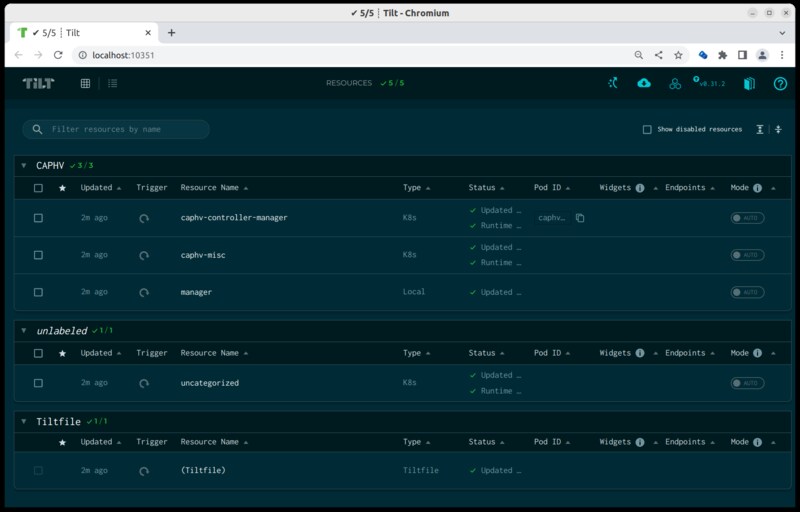
Be sure that all Resources are ok (5/5 in above screenshot).
At the top right side you see an up-arrow icon. You see “Create Hivelocity Cluster” if you hover the button. You can use it to create a new workload cluster.
Open a terminal and execute make watch

The output of make watch updates itself. You can monitor the progress of the CAPHV controller.
Working with baremetal servers takes time. It takes roughly 20 minutes until the ssh port of the first control plane is reachable.
Developing Cluster API Provider Hivelocity
Developing our provider is quite easy. First, you need to install some base requirements. Second, you need to follow the quickstart documents to set up everything related to Hivelocity. Third, you need to configure your Tilt set-up. After having done those three steps, you can start developing with the local Kind cluster and the Tilt UI to create one of the different workload clusters that are already pre-configured.
Why Tilt
Provider Integration development requires a lot of iteration, and the “build, tag, push, update deployment” workflow can be very tedious.
Tilt makes this process much simpler by watching for updates and automatically building and deploying them.
You just need to update the Go code, and if it compiles, the caphv-controller-manager will get updated.
Updating the API of the CRDs
If you update the API in some way, you need to run make generate in order to generate everything related to kubebuilder and the CRDs.
Deleting the cluster
To tear down the workload cluster press the “Delete Workload Cluster” button. After a few minutes the resources should be deleted.
To tear down the kind cluster, use:
$ make delete-cluster
To delete the registry, use: make delete-registry or make delete-cluster-registry.
make help
If you have any trouble finding the right command, then you can use make help to get a list of all available make targets.
Submitting PRs and testing
There are two important commands that you should make use of before creating the PR.
With make verify you can run all linting checks and others. Make sure that all of these checks pass - otherwise the PR cannot be merged. Note that you need to commit all changes for the last checks to pass.
With make test all unit tests are triggered. If they fail out of nowhere, then please re-run them. They are not 100% stable and sometimes there are tests failing due to something related to Kubernetes’ envtest.
With make generate new CRDs are generated, this is necessary if you change the api.
With make watch you can monitor the progress.
Logging
The interesting logs are from the caphv-controller-manager, because these logs got created by the code of this repository.
You can get the logs via kubectl
First you need the exact name of the controller:
❯ kubectl get pods -A | grep caphv-controller
capi-hivelocity-system caphv-controller-manager-7889d9d768-7m8hr 2/2 Running 0 53m
Then you can fetch the logs:
❯ kubectl -n capi-hivelocity-system logs -f caphv-controller-manager-7889d9d768-7m8hr > caphv-controller-manager-7889d9d768-7m8hr.log
You can see these logs via the Tilt UI, too.
For debugging you can reduce the log output with this script:
❯ ./hack/filter-caphv-controller-manager-logs.py caphv-controller-manager-7889d9d768-7m8hr.log | tail
Or:
❯ kubectl -n capi-hivelocity-system logs \
$(kubectl -n capi-hivelocity-system get pods | grep caphv-controller-manager | cut -d' ' -f1) \
| ./hack/filter-caphv-controller-manager-logs.py - | tail
The command make watch shows the last lines of logs, too.
Testing
We use these types (from simple to complex):
- Go unit tests
- envtest from controller-runtime
- End-to-End Tests
The unit tests and envtests get executed via make test-unit.
Please add new tests, if you add new features.
Try to use a simple type. For example, prefer to write a unit test to a test which needs envtest.
CI
We use Github Actions to:
- lint the code, so that it follows best practices
- lint yaml files and markdown (documentation)
- run unit tests
- run e2e tests
Latest Actions
You can see the result of the latest jobs here: github.com/hivelocity/cluster-api-provider-hivelocity/actions
Running Github Actions locally
If you are updating the Github Actions, you can speed up your edit-test feedback loop if you run the actions locally.
You need to install nektos/act.
Then you can have a look at the available jobs:
act -l
Stage Job ID Job name Workflow name Workflow file Events
0 markdown-link-check Broken Links Check PR Markdown links lint-docs-pr.yml pull_request
0 deploy deploy mdBook github pages mdbook.yml push
0 test-release Create a Test Release E2E PR Blocking pr-e2e.yaml pull_request_target
0 manager-image Build and push manager image E2E PR Blocking pr-e2e.yaml pull_request_target
0 golangci lint golangci-lint pr-golangci-lint.yml pull_request
0 shellcheck shellcheck-lint shellcheck pr-shellcheck.yml pull_request
0 starlark run starlark lint starlark pr-starlark-lint.yml pull_request
0 unit-test unit-test unit-test pr-unit-test.yml pull_request
0 verify-code Verify Code Verify PR Code pr-verify-code.yml pull_request
0 verify-pr-content verify PR contents Verify Pull Request pr-verify.yml pull_request_target
0 yamllint yamllint yamllint test pr-yamllint.yml pull_request
1 e2e-basic End-to-End Test Basic E2E PR Blocking pr-e2e.yaml pull_request_target
Then you can call single jobs:
act -j yamllint
[yamllint test/yamllint] 🚀 Start image=catthehacker/ubuntu:act-latest
[yamllint test/yamllint] 🐳 docker pull image=catthehacker/ubuntu:act-latest platform= username= forcePull=true
[yamllint test/yamllint] using DockerAuthConfig authentication for docker pull
[yamllint test/yamllint] 🐳 docker create image=catthehacker/ubuntu:act-latest platform= entrypoint=["tail" "-f" "/dev/null"] cmd=[]
[yamllint test/yamllint] 🐳 docker run image=catthehacker/ubuntu:act-latest platform= entrypoint=["tail" "-f" "/dev/null"] cmd=[]
[yamllint test/yamllint] ☁ git clone 'https://github.com/actions/setup-python' # ref=v4
[yamllint test/yamllint] ⭐ Run Main actions/checkout@v3
...
Actions which are known to work with act:
- golangci
- shellcheck
- starlark
- unit-test
- verify-code
- verify-pr-content
- yamllint
Actions which are known to not work with act:
- markdown-link-check
Using act is optional and not needed, except you want to update the Github Actions. All actions are
available as Makefile targets (see make help), too.
Updating Github Actions
In CI the Github Actions of the main branch get executed.
If you want to update the Github Actions you need to merge the changes to the main branch first.
See docs for pull_request_target
E2E tests
End-to-end tests run in CI, so that changes get automatically tested.
Running local e2e test
If you are interested in running the e2e tests locally, then you can use the following commands:
export HIVELOCITY_API_KEY=<api-key>
export CAPHV_LATEST_VERSION=<latest-version>
make test-e2e
You need patience. Running the e2e tests takes roughly 40 minutes.
Updating controller during e2e test
You discovered an error in the code, or you want to add some logging statement while the e2e is running?
Usualy development gets done with Tilt, but you can update the image during an e2e test with these steps:
Re-create the image:
make e2e-image
config=$(yq '.clusters[0].name' .mgt-cluster-kubeconfig.yaml)
kind_cluster_name="${config#kind-}"
# refresh the image
kind load docker-image ghcr.io/hivelocity/caphv-staging:e2e --name=$kind_cluster_name
# restart the pod
kubectl rollout restart deployment -n capi-hivelocity-system caphv-controller-manager
check make watch
Docs
The markdown files are in the directory docs/book/src.
You can build the docs like this:
make -C docs/book/ build
Then open your web browser:
open ./docs/book/book/index.html
Via Github Actions, the docs get uploaded to: hivelocity.github.io/cluster-api-provider-hivelocity/
You can check links by using nektos/act:
act -j markdown-link-check
Reference Guide
CRD Reference
Glossary
Ports
Jobs
Code of Conduct
Contributing
Version Support
Packages:
infrastructure.cluster.x-k8s.io/v1alpha1
Package v1alpha1 contains API Schema definitions for the infrastructure v1alpha1 API group
Resource Types:ControllerGeneratedStatus
(Appears on:HivelocityMachineSpec)
ControllerGeneratedStatus contains all status information which is important to persist.
| Field | Description |
|---|---|
provisioningStateProvisioningState |
(Optional)
Information tracked by the provisioner. |
lastUpdatedKubernetes meta/v1.Time |
(Optional)
Time stamp of last update of status. |
HivelocityCluster
HivelocityCluster is the Schema for the hivelocityclusters API.
| Field | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta |
Refer to the Kubernetes API documentation for the fields of the
metadata field.
|
||||||||
specHivelocityClusterSpec |
|
||||||||
statusHivelocityClusterStatus |
HivelocityClusterSpec
(Appears on:HivelocityCluster, HivelocityClusterTemplateResource)
HivelocityClusterSpec defines the desired state of HivelocityCluster.
| Field | Description |
|---|---|
controlPlaneEndpointCluster API api/v1beta1.APIEndpoint |
(Optional)
ControlPlaneEndpoint represents the endpoint used to communicate with the control plane. |
controlPlaneRegionRegion |
ControlPlaneRegion is a Hivelocity Region (LAX2, …). |
hivelocitySecretRefHivelocitySecretRef |
HivelocitySecret is a reference to a Kubernetes Secret. |
sshKeySSHKey |
(Optional)
SSHKey is cluster wide. Valid value is a valid SSH key name. |
HivelocityClusterStatus
(Appears on:HivelocityCluster)
HivelocityClusterStatus defines the observed state of HivelocityCluster.
| Field | Description |
|---|---|
readybool |
|
failureDomainsCluster API api/v1beta1.FailureDomains |
|
conditionsCluster API api/v1beta1.Conditions |
HivelocityClusterTemplate
HivelocityClusterTemplate is the Schema for the hivelocityclustertemplates API.
| Field | Description | ||
|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta |
Refer to the Kubernetes API documentation for the fields of the
metadata field.
|
||
specHivelocityClusterTemplateSpec |
|
HivelocityClusterTemplateResource
(Appears on:HivelocityClusterTemplateSpec)
HivelocityClusterTemplateResource contains spec for HivelocityClusterSpec.
| Field | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
metadataCluster API api/v1beta1.ObjectMeta |
(Optional)
Refer to the Kubernetes API documentation for the fields of the
metadata field.
|
||||||||
specHivelocityClusterSpec |
|
HivelocityClusterTemplateSpec
(Appears on:HivelocityClusterTemplate)
HivelocityClusterTemplateSpec defines the desired state of HivelocityClusterTemplate.
| Field | Description |
|---|---|
templateHivelocityClusterTemplateResource |
HivelocityDeviceType
(string alias)
(Appears on:HivelocityMachineSpec)
HivelocityDeviceType defines the Hivelocity device type.
HivelocityMachine
HivelocityMachine is the Schema for the hivelocitymachines API.
| Field | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta |
Refer to the Kubernetes API documentation for the fields of the
metadata field.
|
||||||||
specHivelocityMachineSpec |
|
||||||||
statusHivelocityMachineStatus |
HivelocityMachineSpec
(Appears on:HivelocityMachine, HivelocityMachineTemplateResource)
HivelocityMachineSpec defines the desired state of HivelocityMachine.
| Field | Description |
|---|---|
providerIDstring |
(Optional)
ProviderID is the unique identifier as specified by the cloud provider. |
typeHivelocityDeviceType |
Type is the Hivelocity Machine Type for this machine. |
imageNamestring |
ImageName is the reference to the Machine Image from which to create the device. |
statusControllerGeneratedStatus |
(Optional)
Status contains all status information of the controller. Do not edit these values! |
HivelocityMachineStatus
(Appears on:HivelocityMachine)
HivelocityMachineStatus defines the observed state of HivelocityMachine.
| Field | Description |
|---|---|
readybool |
(Optional)
Ready is true when the provider resource is ready. |
addresses[]Cluster API api/v1beta1.MachineAddress |
Addresses contains the machine’s associated addresses. |
regionRegion |
Region contains the name of the Hivelocity location the device is running. |
powerStatestring |
(Optional)
PowerState is the state of the device for this machine. |
failureReasonCluster API errors.MachineStatusError |
(Optional)
FailureReason will be set in the event that there is a terminal problem reconciling the Machine and will contain a succinct value suitable for machine interpretation. |
failureMessagestring |
(Optional)
FailureMessage will be set in the event that there is a terminal problem reconciling the Machine and will contain a more verbose string suitable for logging and human consumption. |
conditionsCluster API api/v1beta1.Conditions |
(Optional)
Conditions defines current service state of the HivelocityMachine. |
HivelocityMachineTemplate
HivelocityMachineTemplate is the Schema for the hivelocitymachinetemplates API.
| Field | Description | ||
|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta |
Refer to the Kubernetes API documentation for the fields of the
metadata field.
|
||
specHivelocityMachineTemplateSpec |
|
||
statusHivelocityMachineTemplateStatus |
HivelocityMachineTemplateResource
(Appears on:HivelocityMachineTemplateSpec)
HivelocityMachineTemplateResource describes the data needed to create am HivelocityMachine from a template.
| Field | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
metadataCluster API api/v1beta1.ObjectMeta |
(Optional)
Standard object’s metadata. Refer to the Kubernetes API documentation for the fields of themetadata field.
|
||||||||
specHivelocityMachineSpec |
Spec is the specification of the desired behavior of the machine.
|
HivelocityMachineTemplateSpec
(Appears on:HivelocityMachineTemplate)
HivelocityMachineTemplateSpec defines the desired state of HivelocityMachineTemplate.
| Field | Description |
|---|---|
templateHivelocityMachineTemplateResource |
HivelocityMachineTemplateStatus
(Appears on:HivelocityMachineTemplate)
HivelocityMachineTemplateStatus defines the observed state of HivelocityMachineTemplate.
| Field | Description |
|---|---|
capacityKubernetes core/v1.ResourceList |
(Optional)
Capacity defines the resource capacity for this machine. This value is used for autoscaling from zero operations as defined in: https://github.com/kubernetes-sigs/cluster-api/blob/main/docs/proposals/20210310-opt-in-autoscaling-from-zero.md |
conditionsCluster API api/v1beta1.Conditions |
(Optional)
Conditions defines current service state of the HivelocityMachineTemplate. |
HivelocityMachineTemplateWebhook
HivelocityMachineTemplateWebhook implements a custom validation webhook for HivelocityMachineTemplate.
HivelocityRemediation
HivelocityRemediation is the Schema for the hivelocityremediations API.
| Field | Description | ||
|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta |
(Optional)
Refer to the Kubernetes API documentation for the fields of the
metadata field.
|
||
specHivelocityRemediationSpec |
(Optional)
|
||
statusHivelocityRemediationStatus |
(Optional) |
HivelocityRemediationSpec
(Appears on:HivelocityRemediation, HivelocityRemediationTemplateResource)
HivelocityRemediationSpec defines the desired state of HivelocityRemediation.
| Field | Description |
|---|---|
strategyRemediationStrategy |
Strategy field defines remediation strategy. |
HivelocityRemediationStatus
(Appears on:HivelocityRemediation, HivelocityRemediationTemplateStatus)
HivelocityRemediationStatus defines the observed state of HivelocityRemediation.
| Field | Description |
|---|---|
phasestring |
(Optional)
Phase represents the current phase of machine remediation. E.g. Pending, Running, Done etc. |
retryCountint |
(Optional)
RetryCount can be used as a counter during the remediation. Field can hold number of reboots etc. |
lastRemediatedKubernetes meta/v1.Time |
(Optional)
LastRemediated identifies when the host was last remediated |
HivelocityRemediationTemplate
HivelocityRemediationTemplate is the Schema for the hivelocityremediationtemplates API.
| Field | Description | ||
|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta |
(Optional)
Refer to the Kubernetes API documentation for the fields of the
metadata field.
|
||
specHivelocityRemediationTemplateSpec |
(Optional)
|
||
statusHivelocityRemediationTemplateStatus |
(Optional) |
HivelocityRemediationTemplateResource
(Appears on:HivelocityRemediationTemplateSpec)
HivelocityRemediationTemplateResource describes the data needed to create a HivelocityRemediation from a template.
| Field | Description | ||
|---|---|---|---|
specHivelocityRemediationSpec |
Spec is the specification of the desired behavior of the HivelocityRemediation.
|
HivelocityRemediationTemplateSpec
(Appears on:HivelocityRemediationTemplate)
HivelocityRemediationTemplateSpec defines the desired state of HivelocityRemediationTemplate.
| Field | Description |
|---|---|
templateHivelocityRemediationTemplateResource |
HivelocityRemediationTemplateStatus
(Appears on:HivelocityRemediationTemplate)
HivelocityRemediationTemplateStatus defines the observed state of HivelocityRemediationTemplate.
| Field | Description |
|---|---|
statusHivelocityRemediationStatus |
HivelocityRemediationStatus defines the observed state of HivelocityRemediation |
HivelocitySecretRef
(Appears on:HivelocityClusterSpec)
HivelocitySecretRef defines the name of the Secret and the relevant key in the secret to access the Hivelocity API.
| Field | Description |
|---|---|
namestring |
(Optional) |
keystring |
(Optional) |
ProvisioningState
(string alias)
(Appears on:ControllerGeneratedStatus)
ProvisioningState defines the states the provisioner will report the host has having.
| Value | Description |
|---|---|
"associate-device" |
StateAssociateDevice . |
"delete" |
StateDeleteDevice . |
"delete-deprovision" |
StateDeleteDeviceDeProvision . |
"delete-dissociate" |
StateDeleteDeviceDissociate . |
"provisioned" |
StateDeviceProvisioned . |
"" |
StateNone means the state is unknown. |
"provision-device" |
StateProvisionDevice . |
"verify-associate" |
StateVerifyAssociate . |
Region
(string alias)
(Appears on:HivelocityClusterSpec, HivelocityMachineStatus)
Region is a Hivelocity Location
RemediationStrategy
(Appears on:HivelocityRemediationSpec)
RemediationStrategy describes how to remediate machines.
| Field | Description |
|---|---|
typeRemediationType |
(Optional)
Type of remediation. |
retryLimitint |
(Optional)
Sets maximum number of remediation retries. |
timeoutKubernetes meta/v1.Duration |
Sets the timeout between remediation retries. |
RemediationType
(string alias)
(Appears on:RemediationStrategy)
RemediationType defines the type of remediation.
| Value | Description |
|---|---|
"Reboot" |
RemediationTypeReboot sets RemediationType to Reboot. |
ResourceLifecycle
(string alias)
ResourceLifecycle configures the lifecycle of a resource.
| Value | Description |
|---|---|
"owned" |
ResourceLifecycleOwned is the value we use when tagging resources to indicate that the resource is considered owned and managed by the cluster, and in particular that the lifecycle is tied to the lifecycle of the cluster. |
"shared" |
ResourceLifecycleShared is the value we use when tagging resources to indicate that the resource is shared between multiple clusters, and should not be destroyed if the cluster is destroyed. |
SSHKey
(Appears on:HivelocityClusterSpec)
SSHKey defines the SSHKey for Hivelocity.
| Field | Description |
|---|---|
namestring |
Name of SSH key. |
Glossary
Table of Contents
A | B | C | D | E | H | I | K | L| M | N | O | P | R | S | T | W
A
Add-ons
Services beyond the fundamental components of Kubernetes.
- Core Add-ons: Addons that are required to deploy a Kubernetes-conformant cluster: DNS, kube-proxy, CNI.
- Additional Add-ons: Addons that are not required for a Kubernetes-conformant cluster (e.g. metrics/Heapster, Dashboard).
B
Bootstrap
The process of turning a server into a Kubernetes node. This may involve assembling data to provide when creating the server that backs the Machine, as well as runtime configuration of the software running on that server.
Bootstrap cluster
A temporary cluster that is used to provision a Target Management cluster.
Bootstrap provider
Refers to a provider that implements a solution for the bootstrap process. Bootstrap provider’s interaction with Cluster API is based on what is defined in the Cluster API contract.
See CABPK.
C
CAEP
Cluster API Enhancement Proposal - patterned after KEP. See template
CAPI
Core Cluster API
CAPA
Cluster API Provider AWS
CABPK
Cluster API Bootstrap Provider Kubeadm
CABPOCNE
Cluster API Bootstrap Provider Oracle Cloud Native Environment (OCNE)
CACPOCNE
Cluster API Control Plane Provider Oracle Cloud Native Environment (OCNE)
CAPC
Cluster API Provider CloudStack
CAPD
Cluster API Provider Docker
CAPDO
Cluster API Provider DigitalOcean
CAPG
Cluster API Google Cloud Provider
CAPH
Cluster API Provider Hetzner
CAPHV
Cluster API Provider Hivelocity
CAPIBM
Cluster API Provider IBM Cloud
CAPIO
Cluster API Operator
CAPM3
Cluster API Provider Metal3
CAPN
Cluster API Provider Nested
CAPX
Cluster API Provider Nutanix
CAPKK
Cluster API Provider KubeKey
CAPK
Cluster API Provider Kubevirt
CAPO
Cluster API Provider OpenStack
CAPOSC
Cluster API Provider Outscale
CAPOCI
Cluster API Provider Oracle Cloud Infrastructure (OCI)
CAPV
Cluster API Provider vSphere
CAPVC
Cluster API Provider vcluster
CAPVCD
Cluster API Provider VMware Cloud Director
CAPZ
Cluster API Provider Azure
CAIPAMIC
Cluster API IPAM Provider In Cluster
Cloud provider
Or Cloud service provider
Refers to an information technology (IT) company that provides computing resources (e.g. AWS, Azure, Google, etc.).
Cluster
A full Kubernetes deployment. See Management Cluster and Workload Cluster.
ClusterClass
A collection of templates that define a topology (control plane and workers) to be used to continuously reconcile one or more Clusters. See ClusterClass
Cluster API
Or Cluster API project
The Cluster API sub-project of the SIG-cluster-lifecycle. It is also used to refer to the software components, APIs, and community that produce them.
See core provider
Cluster API Runtime
The Cluster API execution model, a set of controllers cooperating in managing the Kubernetes cluster lifecycle.
Cluster Infrastructure
or Kubernetes Cluster Infrastructure
Defines the infrastructure that supports a Kubernetes cluster, like e.g. VPC, security groups, load balancers, etc. Please note that in the context of managed Kubernetes some of those components are going to be provided by the corresponding abstraction for a specific Cloud provider (EKS, OKE, AKS etc), and thus Cluster API should not take care of managing a subset or all those components.
Contract
Or Cluster API contract
Defines a set of rules a provider is expected to comply with in order to interact with Cluster API. Those rules can be in the form of CustomResourceDefinition (CRD) fields and/or expected behaviors to be implemented.
Control plane
The set of Kubernetes services that form the basis of a cluster. See also https://kubernetes.io/docs/concepts/#kubernetes-control-plane There are two variants:
- Self-provisioned: A Kubernetes control plane consisting of pods or machines wholly managed by a single Cluster API deployment.
- External or Managed: A control plane offered and controlled by some system other than Cluster API (e.g., GKE, AKS, EKS, IKS).
Control plane provider
Refers to a provider that implements a solution for the management of a Kubernetes control plane. Control plane provider’s interaction with Cluster API is based on what is defined in the Cluster API contract.
See KCP.
Core provider
Refers to a provider that implements Cluster API core controllers; if you consider that the first project that must be deployed in a management Cluster is Cluster API itself, it should be clear why the Cluster API project is also referred to as the core provider.
See CAPI.
D
Default implementation
A feature implementation offered as part of the Cluster API project and maintained by the CAPI core team; For example KCP is a default implementation for a control plane provider.
E
External patch
Patch generated by an external component using Runtime SDK. Alternative to inline patch.
External patch extension
A runtime extension that implements a topology mutation hook.
H
Horizontal Scaling
The ability to add more machines based on policy and well-defined metrics. For example, add a machine to a cluster when CPU load average > (X) for a period of time (Y).
Host
see Server
I
Infrastructure provider
Refers to a provider that implements provisioning of infrastructure/computational resources required by the Cluster or by Machines (e.g. VMs, networking, etc.). Infrastructure provider’s interaction with Cluster API is based on what is defined in the Cluster API contract.
Clouds infrastructure providers include AWS, Azure, or Google; while VMware, MAAS, or metal3.io can be defined as bare metal providers. When there is more than one way to obtain resources from the same infrastructure provider (e.g. EC2 vs. EKS in AWS) each way is referred to as a variant.
For a complete list of providers see Provider Implementations.
Inline patch
A patch defined inline in a ClusterClass. An alternative to an external patch.
In-place mutable fields
Fields which changes would only impact Kubernetes objects or/and controller behaviour but they won’t mutate in any way provider infrastructure nor the software running on it. In-place mutable fields are propagated in place by CAPI controllers to avoid the more elaborated mechanics of a replace rollout. They include metadata, MinReadySeconds, NodeDrainTimeout, NodeVolumeDetachTimeout and NodeDeletionTimeout but are not limited to be expanded in the future.
Instance
see Server
Immutability
A resource that does not mutate. In Kubernetes we often state the instance of a running pod is immutable or does not change once it is run. In order to make a change, a new pod is run. In the context of Cluster API we often refer to a running instance of a Machine as being immutable, from a Cluster API perspective.
IPAM provider
Refers to a provider that allows Cluster API to interact with IPAM solutions.
IPAM provider’s interaction with Cluster API is based on the IPAddressClaim and IPAddress API types.
K
Kubernetes-conformant
Or Kubernetes-compliant
A cluster that passes the Kubernetes conformance tests.
k/k
Refers to the main Kubernetes git repository or the main Kubernetes project.
KCP
Kubeadm Control plane Provider
L
Lifecycle hook
A Runtime Hook that allows external components to interact with the lifecycle of a Cluster.
See Implementing Lifecycle Hooks
M
Machine
Or Machine Resource
The Custom Resource for Kubernetes that represents a request to have a place to run kubelet.
See also: Server
Manage a cluster
Perform create, scale, upgrade, or destroy operations on the cluster.
Managed Kubernetes
Managed Kubernetes refers to any Kubernetes cluster provisioning and maintenance abstraction, usually exposed as an API, that is natively available in a Cloud provider. For example: EKS, OKE, AKS, GKE, IBM Cloud Kubernetes Service, DOKS, and many more throughout the Kubernetes Cloud Native ecosystem.
Managed Topology
See Topology
Management cluster
The cluster where one or more Infrastructure Providers run, and where resources (e.g. Machines) are stored. Typically referred to when you are provisioning multiple workload clusters.
Multi-tenancy
Multi tenancy in Cluster API defines the capability of an infrastructure provider to manage different credentials, each one of them corresponding to an infrastructure tenant.
Please note that up until v1alpha3 this concept had a different meaning, referring to the capability to run multiple instances of the same provider, each one with its own credentials; starting from v1alpha4 we are disambiguating the two concepts.
See Multi-tenancy and Support multiple instances.
N
Node pools
A node pool is a group of nodes within a cluster that all have the same configuration.
O
Operating system
Or OS
A generically understood combination of a kernel and system-level userspace interface, such as Linux or Windows, as opposed to a particular distribution.
P
Patch
A set of instructions describing modifications to a Kubernetes object. Examples include JSON Patch and JSON Merge Patch.
Pivot
Pivot is a process for moving the provider components and declared cluster-api resources from a Source Management cluster to a Target Management cluster.
The pivot process is also used for deleting a management cluster and could also be used during an upgrade of the management cluster.
Provider
Or Cluster API provider
This term was originally used as abbreviation for Infrastructure provider, but currently it is used to refer to any project that can be deployed and provides functionality to the Cluster API management Cluster.
See Bootstrap provider, Control plane provider, Core provider, Infrastructure provider, IPAM provider Runtime extension provider.
Provider components
Refers to the YAML artifact published as part of the release process for providers; it usually includes Custom Resource Definitions (CRDs), Deployments (to run the controller manager), RBAC, etc.
In some cases, the same expression is used to refer to the instances of above components deployed in a management cluster.
Provider repository
Refers to the location where the YAML for provider components are hosted; usually a provider repository hosts many version of provider components, one for each released version.
R
Runtime Extension
An external component which is part of a system built on top of Cluster API that can handle requests for a specific Runtime Hook.
See Runtime SDK
Runtime Extension provider
Refers to a provider that implements one or more runtime extensions. Runtime Extension provider’s interaction with Cluster API are based on the Open API spec for runtime hooks.
Runtime Hook
A single, well identified, extension point allowing applications built on top of Cluster API to hook into specific moments of the Cluster API Runtime, e.g. BeforeClusterUpgrade, TopologyMutationHook.
See Runtime SDK
Runtime SDK
A developer toolkit required to build Runtime Hooks and Runtime Extensions.
See Runtime SDK
S
Scaling
Unless otherwise specified, this refers to horizontal scaling.
Stacked control plane
A control plane node where etcd is colocated with the Kubernetes API server, and is running as a static pod.
Server
The infrastructure that backs a Machine Resource, typically either a cloud instance, virtual machine, or physical host.
T
Topology
A field in the Cluster object spec that allows defining and managing the shape of the Cluster’s control plane and worker machines from a single point of control. The Cluster’s topology is based on a ClusterClass. Sometimes it is also referred as a managed topology.
See ClusterClass
Topology Mutation Hook
A Runtime Hook that allows external components to generate patches for customizing Kubernetes objects that are part of a Cluster topology.
W
Workload Cluster
A cluster created by a ClusterAPI controller, which is not a bootstrap cluster, and is meant to be used by end-users, as opposed to by CAPI tooling.
WorkerClass
A collection of templates that define a set of worker nodes in the cluster. A ClusterClass contains zero or more WorkerClass definitions.
See ClusterClass
Ports
| Name | Port Number | Description |
|---|---|---|
metrics | Port that exposes the metrics. This can be customized by setting the --metrics-bind-addr flag when starting the manager. The default is to only listen on localhost:8080 | |
webhook | 9443 | Webhook server port. To disable this set --webhook-port flag to 0. |
health | 9440 | Port that exposes the health endpoint. This can be customized by setting the --health-addr flag when starting the manager. |
profiler | Expose the pprof profiler. By default is not configured. Can set the --profiler-address flag. e.g. --profiler-address 6060 |
Jobs
TBD
Kubernetes Community Code of Conduct
Please refer to our Kubernetes Community Code of Conduct
Contributing Guidelines
Read the following guide if you’re interested in contributing to cluster-api-provider-hivelocity.
Finding Things That Need Help
If you’re new to the project and want to help, but don’t know where to start, we have a semi-curated list of issues that should not need deep knowledge of the system. Have a look and see if anything sounds interesting. Before starting to work on the issue, make sure that it doesn’t have a lifecycle/active label. If the issue has been assigned, reach out to the assignee. Alternatively, read some of the docs on other controllers and try to write your own, file and fix any/all issues that come up, including gaps in documentation!
If you’re a more experienced contributor, looking at unassigned issues in the next release milestone is a good way to find work that has been prioritized. For example, if the latest minor release is v1.0, the next release milestone is v1.1.
Help and contributions are very welcome in the form of code contributions but also in helping to moderate office hours, triaging issues, fixing/investigating flaky tests, cutting releases, helping new contributors with their questions, reviewing proposals, etc.
Branches
Cluster API has two types of branches: the main branch and release-X branches.
The main branch is where development happens. All the latest and greatest code, including breaking changes, happens on main.
The release-X branches contain stable, backwards compatible code. On every major or minor release, a new branch is created. It is from these branches that minor and patch releases are tagged. In some cases, it may be necessary to open PRs for bugfixes directly against stable branches, but this should generally not be the case.
Contributing a Patch
- If working on an issue, signal other contributors that you are actively working on it using
/lifecycle active. - Fork the desired repo, develop and test your code changes.
- See the Development Guide for more instructions on setting up your environment and testing changes locally.
- Submit a pull request.
- All PRs should be labeled with one of the following kinds
/kind featurefor PRs releated to adding new features/tests/kind bugfor PRs releated to bug fixes and patches/kind api-changefor PRs releated to adding, removing, or otherwise changing an API/kind cleanupfor PRs releated to code refactoring and cleanup/kind deprecationfor PRs related to a feature/enhancement marked for deprecation./kind designfor PRs releated to design proposals/kind documentationfor PRs releated to documentation/kind failing-testfor PRs releated to to a consistently or frequently failing test./kind flakefor PRs related to a flaky test./kind otherfor PRs releated to updating dependencies, minor changes or other
- All code PR must be have a title starting with one of
- ⚠️ (
⚠, major or breaking changes) - ✨ (
✨, feature additions) - 🐛 (
🐛, patch and bugfixes) - 📖 (
📖, documentation or proposals) - 🌱 (
🌱, minor or other)
- ⚠️ (
- If the PR requires additional action from users switching to a new release, include the string “action required” in the PR release-notes.
- All code changes must be covered by unit tests and E2E tests.
- All new features should come with user documentation.
- All PRs should be labeled with one of the following kinds
- Once the PR has been reviewed and is ready to be merged, commits should be squashed.
- Ensure that commit message(s) are be meaningful and commit history is readable.
All changes must be code reviewed. Coding conventions and standards are explained in the official developer docs. Expect reviewers to request that you avoid common go style mistakes in your PRs.
In case you want to run our E2E tests locally, please refer to Docs / E2E Tests guide.
Version Support
Release Versioning
CAPHV follows the semantic versionining specification:
MAJOR version release for incompatible API changes, MINOR version release for backwards compatible feature additions, and PATCH version release for only bug fixes.
Example versions:
- Minor release:
v0.1.0 - Patch release:
v0.1.1 - Major release:
v1.0.0
Compatibility with Cluster API Versions
CAPHV’s versions are compatible with the following versions of Cluster API
Cluster API v1beta1 (v1.4.x) | |
|---|---|
CAPHV v1alpha1 v1.0.x | ✓ |
CAPHV versions are not released in lock-step with Cluster API releases. Multiple CAPHV minor releases can use the same Cluster API minor release.
For compatibility, check the release notes here to see which v1beta1 Cluster API version each CAPHV version is compatible with.
For example:
- CAPHV v1.0.x is compatible with Cluster API v1.4.x
End-of-Life Timeline
TBD
Compatibility with Kubernetes Versions
CAPHV API versions support all Kubernetes versions that is supported by its compatible Cluster API version:
| API Versions | CAPI v1beta1 (v1.x) |
|---|---|
| CAPHV v1alpha1 (v0.1) | ✓ |
(See Kubernetes support matrix of Cluster API versions).
Tested Kubernetes Versions:
Hivelocity Provider v0.1.x | |
|---|---|
| Kubernetes 1.25.x | ✓ |